
서두용 아무말
최근 사내 SQL 교육을 끝냈다. 한숨 돌리려고 하다 보니 현재 BigQuery에서 사용 중인 로그 외에도 사내 데이터 마트를 BigQuery 로 이전하고 있다는 것이 생각났다. 추가 교육은 가능하면 이제는 피하고 싶지만(언젠가 다루겠지만 제대로 하려는 교육에는 생각보다 더 많은 리소스가 투입되고 기대 효과는 이에 비해 극히 낮다) 어쨌든 최소한 질문이 들어왔을 때를 고민해보는 것은 나쁘지 않고 이렇게 글 쓸 거리도 생각이 나지 않는가.
각설하고. 먼 옛날도 아니고 이제는 BigQuery도 표준 SQL 형태를 지원하고 있기 때문에 기존 RDBMS 기준 SQL을 배운 사람(나 포함)도 손쉽게 사용할 수 있다. 서버리스에서 오는 장점 등은 차치하고라도, (에디터는 영 마음에 안 들기는 하지만) 성능이나 여러 편리한 함수 덕분에 요즘 BigQuery를 나는 매우 아끼고 있으나 이를 다른 사람들은 과연 아낄까 생각해 보았다. 그러다보니 예상되는 장벽이 하나 보였다.
그 이름 바로 ARRAY.
BigQuery는 SQL을 지원하기는 하지만 기본적으로 RDBMS 구조가 아니다. 그래서 RDBMS처럼 테이블을 정규화하고 이를 JOIN으로 엮어서 사용하는 스타 스키마/눈송이 스키마 를 지향하는 경우 성능 향상에 전혀 도움이 되지 않는다. 그 훌륭한 BigQuery의 성능을 제대로 활용할 수 없는 것이다.
BigQuery에서는 최대한 JOIN을 줄일 수 있도록 비정규화된 형태의 데이터 형태를 지향한다. 그리고 이를 위해서 몇 가지 데이터 유형을 지원하는데, 중첩 형태로 지원하는 STRUCT와 1:n 형태를 지원하는 ARRAY다. 그리고 많은 경우 STRUCT보다는 ARRAY가 뱅만배 많이 사용된다. 일단 BigQuery로 들어오는 Google Analytics 로그 데이터를 확인해보자.
그다지 훌륭한 한글화는 아니지만 어쨌든, 저기를 보면 스키마 설명 직전에 ‘BigQuery에서 일부 열에는 중첩된 필드 및 메시지가 있을 수 있습니다.’ 라고 명시하고 있다. 그리고 데이터 유형에 보면 ‘레코드’라고 된 부분이 보일 것이다.
그러하다 저거 다 ARRAY라고 보면 대충 맞는다.
그래서 ARRAY가 뭔지 설명해 본다면?
ARRAY의 개념은 기존 RDBMS와 SQL에 그래도 어느 정도 익숙한 사람들에게라면 일단 테이블을 JOIN 해 둔 형태라고 설명할 수 있다. 그리고 이 것을 JSON 형태로 풀어서 써주고 이러면 저장공간을 절약할 수 있을 것이고, 엔진이 처리 방식이 달라서 이런 모양으로 생겼다고 알려주면 된다.
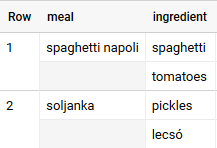
그럼 그것을 어떻게 쓰나요?
잘. (… 죄송합니다.)
물론 이를 쉽고 잘 쓰기 위한 만능 함수가 있으니 바로 UNNEST()다. 이는 해당 ARRAY를 풀어서 작은 테이블로 만들어 준다고 생각하면 된다. ‘왜 굳이 귀찮게 이런 것은 만들었는가’ 싶지만 조금만 손에 익고 핑핑핑 돌아가는 BigQuery를 보다 보면 그런 생각이 다소 걷힐 것이다.
이는 테이블과 같은 역할을 하므로 전체 테이블이 호출된 쿼리라면 본 쿼리 및 서브 쿼리의 FROM 뒤에 테이블 마냥 그냥 써 주어도 된다. 본 쿼리에서 사용하는 경우 JOIN 처럼 쓸 수 있다. (보통 줄여서 ,로 생략해 버리지만 CROSS JOIN이 된다고 보면 무방하다.)
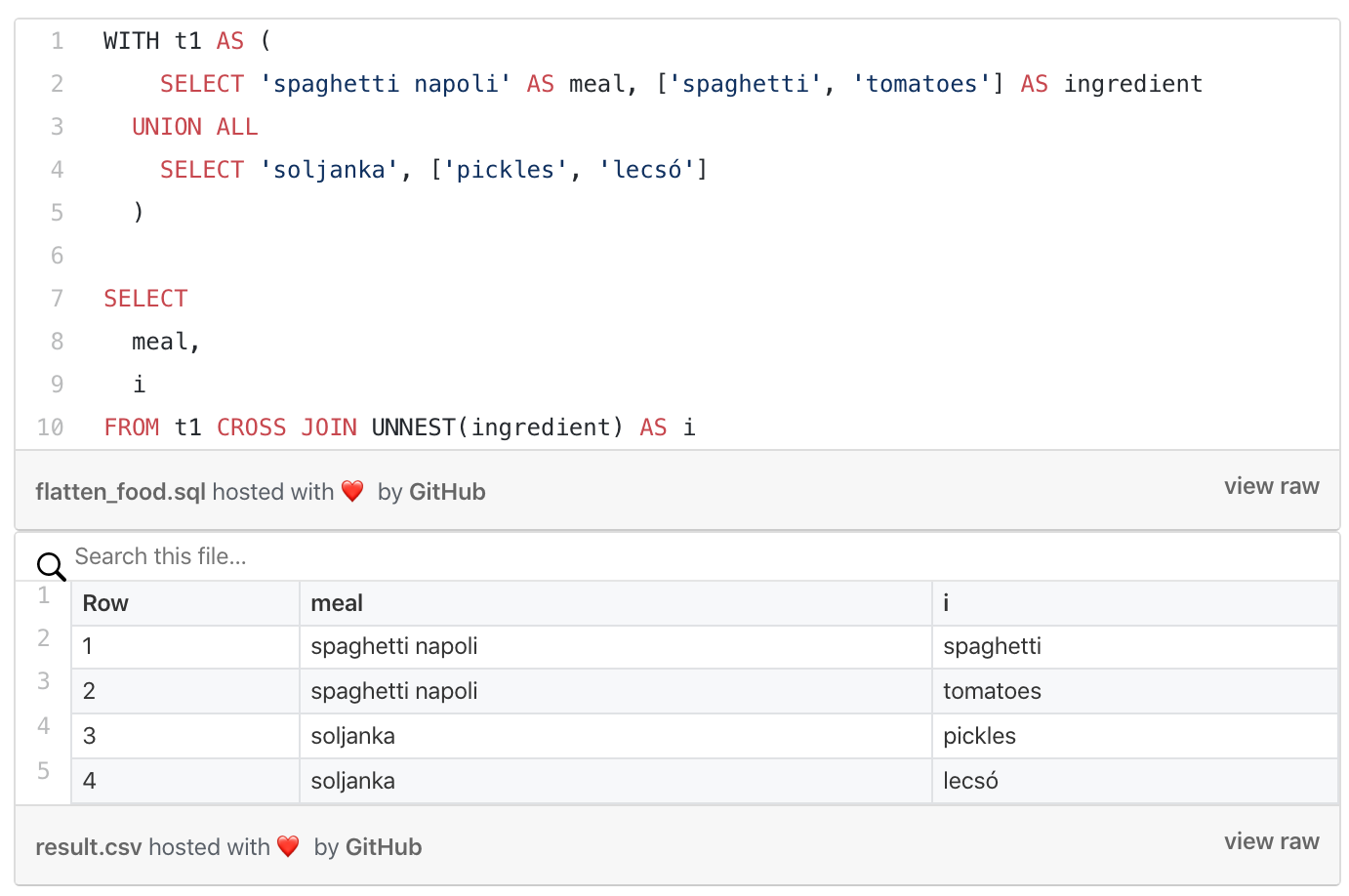
t1은 이전 그림처럼 만들어진 데이터였지만 이 중 ARRAY 형태의 ingredient 라는 컬럼을 UNNEST로 풀어준 후 CROSS JOIN 하면 우리에게 익숙한 꽉 차 있는 2차원 테이블(정규형)이 된다. 그럼 이 상태에서 우리가 아는 대로 지지고 볶고(…) 하면 된다.
다만 항상 이렇게 하는 것은 추천하지 않는다. 물론 이를 쫙 펴서 group by 등을 하거나 다양하게 쓸 이유가 충분하면 이를 써야 하겠지만, BigQuery는 기본적으로 JOIN의 경우 성능이 좋지 않고(물론 그 좋지 않다는 것이 우리가 다른 데에서 경험하던 것보다는 보통 훨씬 좋을 가능성이 많지만…상대적인 것이다)
그렇다면 어쩌란 말이냐.
앞에서 잠시 언급한 대로 UNNEST를 서브쿼리에 써주는 것이다. 이 때의 서브쿼리는 보통 SELECT 뒤에 호출하는 서브쿼리를 말한다. 물론 일반적인 RDBMS에서 이런 식으로 하기는 어렵겠지만 빅쿼리에서의 UNNEST는 기본적으로 FROM 에서 호출하는 원시 테이블에 있는 컬럼을 풀어준 것이므로 가능한 이야기다. 이러면 본 쿼리에서 테이블을 굳이 정규형으로 만들어주지 않고 쓸 수 있으므로 성능상에 도움이 된다.
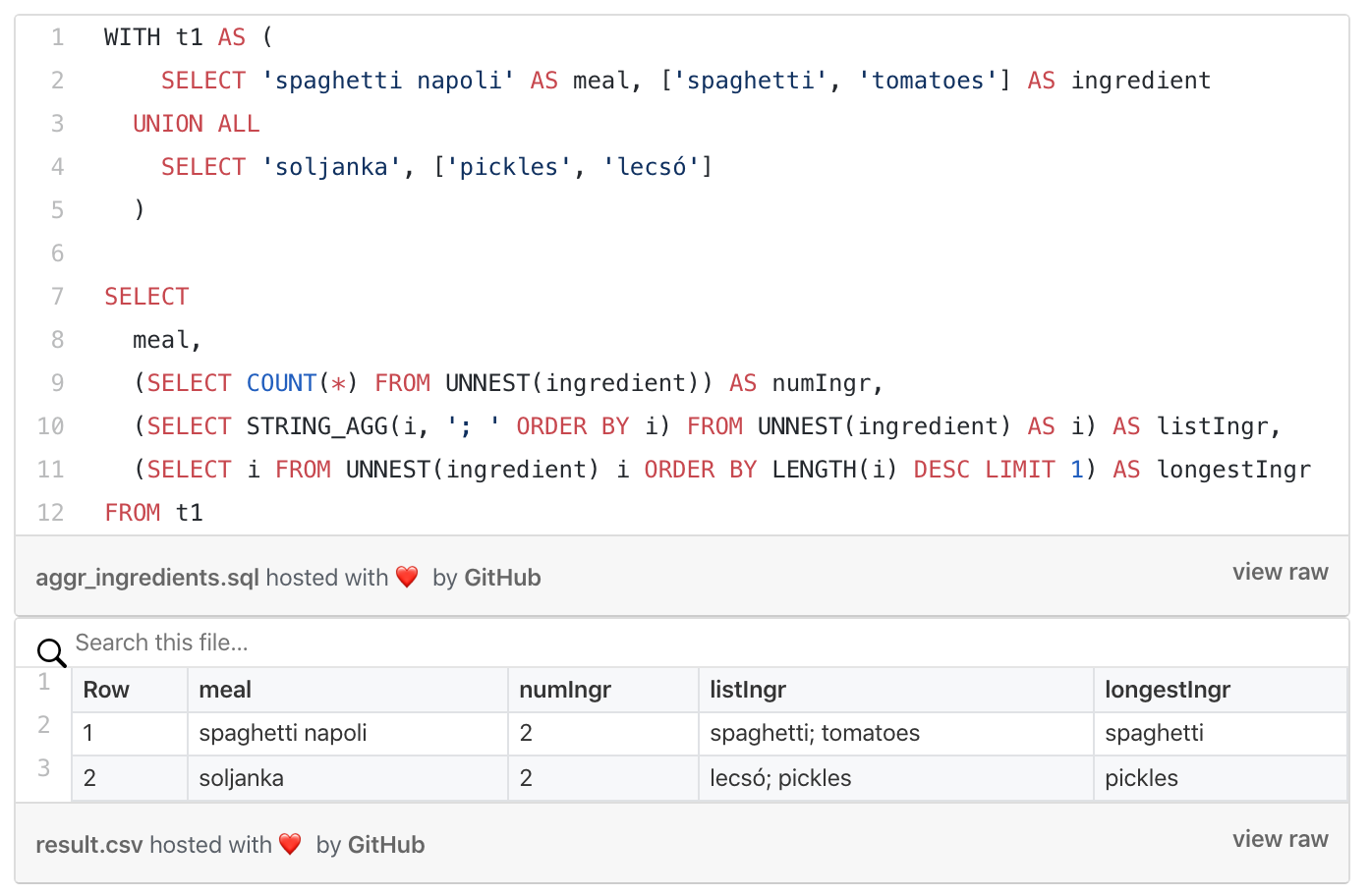
기본 컬럼과 ARRAY 컬럼에서의 간단 통계량 등 하나의 값으로 만들어낼 수 있는 것은 서브쿼리로 만들 수 있다.
이를 잘 응용할 수 있다. 물론 이를 응용하기가 너무나도 어렵다면 어쩔 수 없이라도 그냥 풀어서 쓰는 것이 낫겠지만 가능하다면 이런 식으로 쓰는 것을 연습해 두게 하면 좋을 것이다.
그리고 이걸로 모두 끝…?
당연히 그럴 리 없다(…). 물론, 이렇게 하면 ‘이론적으로는’ 웬만한 것은 다 해결할 수 있다. 하지만 자주 사용되는 서브쿼리 같은 경우 사용자들에게 매번 같은 서브쿼리를 길게 쳐서 쓰라고 하면 사람들이 쓰겠는가. 물론 울며 겨자먹기로 쓸 수도 있겠지만 이건 이 글의 제목인 ‘쉽게 쓰기’와 맞지 않는다.
그래서 준비해 보았습니다. UDF (User Defined Function)…
타 경쟁제품 대비 BigQuery의 장점으로 꼽히는 것 중 하나가 UDF를 지원한다는 것이다. 그러므로 이를 사용해서 사용자들이 ARRAY를 보다 편하게 쓸 수 있도록 만들 수 있다. 특히 위의 subquery의 경우, 자주 쓰는 것은 미리 UDF로 만들어 둔 후 쓰게 하면, 일반 SQL함수 쓰는 것처럼 ARRAY에 편하게 접근할 수 있다. BigQuery의 UDF는 Javascript와 SQL(!)을 지원하므로, 익숙한 SQL문법을 사용해서 UDF를 만들 수도 있다.
대표적인 것이 GA 로그에서 CustomDimension의 값을 가져오는 함수다.
1
2
CREATE TEMP FUNCTION customDimensionByIndex(indx INT64, arr ARRAY<STRUCT<index INT64, value STRING>>) AS (
(SELECT x.value FROM UNNEST(arr) x WHERE indx=x.index));
arr ARRAY에서 해당 arr.index의 값을 넣어주면 그 인덱스 값에 대한 value 를 반환하는 함수다. 이 함수를 사용한 SQL 구문은 다음과 같다.
1
2
3
4
5
SELECT fullvisitorid, visitid,
customDimensionByIndex(1, hit.customDimensions) as productCategory,
customDimensionByIndex(2, hit.customDimensions) as loyaltyClass
FROM `google.com:analytics-bigquery.LondonCycleHelmet.ga_sessions_20130910`, UNNEST(hits) as hit
LIMIT 100
함수 내의 구문을 subquery로 그대로 사용해도 무방한 쿼리기는 하지만 이 쪽이 훨씬 보기도 좋고 쓰기도 좋다.
이런 함수를 내부 데이터의 구조와 필요에 따라 여러 개 생성해 두고 사용자들에게 제공하거나 교환하면 ARRAY라는 벽을 보다 쉽게 통과할 수 있다.
BigQuery를 잘 사용해 보자.
요약하면, ARRAY는 UNNEST 써서 그냥 다른 테이블인 양 JOIN을 하거나, SUBQUERY로 쓰면 되고, 본인보다 좀 더 잘하는 사람이 UDF를 만들어 줄 수도 있고 아니면 급한 대로 내가 만들자(SQL로…). 가 될 수 있다.
이왕 BigQuery를 쓰게 된다면, 데이터를 관리하는 쪽에서는 적재할 때부터 기존의 RDBMS 형식으로 그대로 가져오기보다 BigQuery의 내용과 성능을 최대한으로 뽑아먹을 수 있는 구조를 고민해보고 가져왔으면 좋겠다. 그리고 그 것을 사용자들이 쓰기 쉽게 하는 것이 중요하다. 사용자는 일단 편한대로 쓰더라도 가능한 한 달라진 것을 조금이라도 쳐다보려고 하는 것이 중요하다. 물론 아무리 좋은 것이라도 변화에는 돈과 시간과 노력 등의 비용이 잔뜩 들고 힘들지만, 어차피 변하는 것이라면 가능한 한 좋은 방향으로 모두가 변할 수 있도록 노력해야겠다.
(그림: https://towardsdatascience.com/https-medium-com-martin-weitzmann-bigquery-sql-on-nested-data-cf9589c105f4)