
들어가며
우리는 여러 가지 이유로, 여러 가지 용도에 사용하기 위해 데이터를 조회합니다. 많은 경우 SQL기반의 데이터 처리 엔진에 SQL 을 사용해서 데이터를 조회하게 됩니다. 이 때, 기본적으로 문법에 맞춰서 데이터를 조회하면 데이터가 잘못 나올 일은 극히 드뭅니다. 하지만 간혹 생각과 다른 데이터가 나온다거나, 잘 돌아가는 지를 확인하고 싶은데 쿼리가 무거울 것 같아서 무조건 돌려보기 애매하다거나, 별 것 아닌 쿼리라고 생각했는데 데이터 조회가 오래 걸리거나 하는 일이 발생합니다. 정말 어쩔 수 없는 경우도 있지만, 상당수의 경우는 쿼리를 좀 더 예쁘게 짜면 전반적인 쿼리 성능을 높일 수 있습니다. 이를 위한 작업을 흔히 ‘쿼리 튜닝’이라고 합니다.
쿼리 튜닝하는 법
이런 쿼리 튜닝을 위해 우선적으로 선행되어야 할 작업은 쿼리가 어떻게 실행되는 지를 아는 것입니다. 대부분의 SQL처리 엔진에서는 SQL 문장을 받으면 이를 어떤 식으로 수행할 지에 대한 계획을 세우는데, 이를 ‘쿼리 실행 계획(Query Plan)’ 이라고 합니다. 그리고 대부분의 SQL처리 엔진에서는 이런 쿼리 실행 계획을 확인할 수 있습니다. 이를 확인할 때는 일반적으로 원하는 쿼리 문 앞에 EXPLAIN을 사용해서 다음과 같은 방식으로 나타냅니다.
EXPLAIN query_statement
그리고 이 EXPLAIN을 사용하는 방식은 Presto(프레스토)에서도 동일하게 사용 가능합니다. 하지만 프레스토의 경우 다양한 데이터 소스 위에서 동작하는 분산 처리 SQL엔진이므로 다른 데이터베이스에서의 실행 계획과 다소 다릅니다.
사내에서 데이터에 접근할 때는 대부분 제플린에서 프레스토에 연결해서 사용하므로, 프레스토의 쿼리 실행 계획을 이해할 줄 알면 데이터를 조회하는 데에 큰 도움이 됩니다.
하지만 GUI가 잘 되어 있는 SQL 클라이언트에 익숙해진 사람들이 보기에는 그다지 보기 좋지 않습니다(…). 또한 예전에 CLI로 SQL을 사용하던 사람들에게는 용어가 그다지 익숙하지 않아서 역시나 그다지 보기 좋지 않습니다.
(예는 사내에서 사용하는 제플린+프레스토 에서의 실제 실행 결과로, 테이블 이름은 숨겼습니다.)
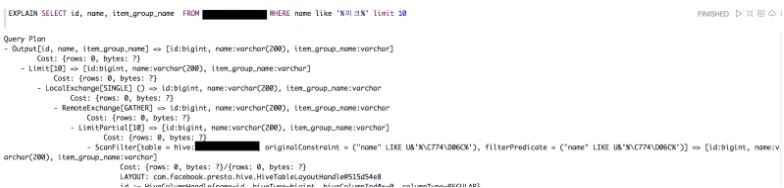
하지만 최소한 계단 형태라도 나오는 게 어디인가 싶습니다(…). 그리고 천천히 뜯어보면 그다지 어렵지 않습니다. 특히, 프레스토의 최소한의 실행 구조와 용어를 알고 뜯어보면 DB 실행 계획 만큼 쉽습니다.
프레스토의 쿼리 실행 형태는 기본적으로 다음과 같습니다.
- ANSI-SQL로 작성된 프레스토에서 실행 가능한 쿼리 문을 받습니다.
- 프레스토 워커에서 실행할 수 있는 쿼리 형태로 내부적으로 변환합니다.
- 실행 단계별로 나눕니다.
- 각 단계마다 분할해서 수행 가능한 업무 단위로 할 일을 쪼갭니다. 각 일은 입력 데이터와 출력 데이터가 존재하는 블랙박스 형태로 만들어져서 fragment(프레스토의 단일 노드 혹은 여러 노드로 만들어진 일하는 단위. 각 부분/각각의 곳 정도로 나타냈다)에서 실행됩니다.
- 부분 간에 필요시 데이터를 교환할 수 있는 연결고리를 구성합니다.
위의 내용을 기억해 두고, 앞서 예시로 든 쿼리를 살펴 보겠습니다. 위의 쿼리는 간단한 SELECT-FROM-WHERE절로 일부만 보기 위해 LIMIT 10을 사용했습니다.
- 우선 크게 분기가 없는 하나의 트리로, 순차적으로 실행되는 것을 알 수 있습니다.
- 가장 안쪽 노드부터 살펴봅니다. 보통 각 부분별로 header-body 형태로 이루어져 있는데, header에 키워드가 들어가 있고 body에는 해당 키워드 실행을 위한 상세 내용이 들어가게 된다. 여기서는 일단 header로 내용을 파악해 보도록 하겠습니다. ScanFilter라는 header가 있는데, 이는 말 그대로 조건절(Where)로 데이터를 필터링하는 부분입니다.
- LimitPartial은 limit 문구를 수행하기 위해 필터링을 수행한 워커에서 데이터 일부를 가져오는 작업입니다.
- RemoteExchange, LocalExchange는 각 노드의 데이터를 모으는 작업입니다.
- 모은 데이터에서 최종 limit을 실행하고 이를 output으로 내놓습니다.
참 쉽죠(!!).

그러면 조금 더 복잡한, 간단한 JOIN과 집계 기능 사용한 쿼리문의 실행 계획을 살펴 보도록 하겠습니다.
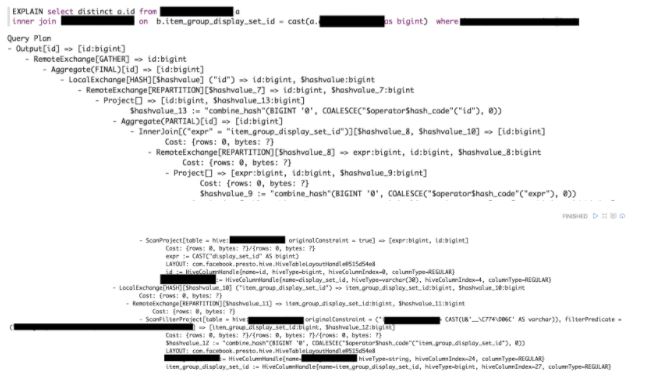
갑자기 길어진 것 같아서 조금 현기증이 나지만 역시나 찬찬히 뜯어보면 별 차이 없습니다.
역시나 하단부터 살펴봅니다.
- 우선 WHERE조건이 해당되는 테이블을 ScanFilter하는 것을 알 수 있습니다. ScanFilterProject라고 되어 있는데 ScanFilter와 무엇이 다른가 조금 살펴보니, body부분에 hashvalue 어쩌고 하는 부분이 있습니다. 여기서 간단하게 프레스토의 각 부분(단일 혹은 여러 노드)에서 일하는 유형을 살펴보겠습니다.
- Single: 단일 부분에서 일을 수행합니다. 첫 번째 쿼리의 경우 모든 단계가 이 상태에서 실행되었습니다.
- Hash: 입력 데이터를 해쉬 함수를 사용해서 여러 부분으로 분산시켜서 일을 수행합니다. 이 단계의 경우 Hash 모드임을 알 수 있습니다.
- Round-Robin: b와 유사하나 Hash 대신 Round-Robin 방식(순차적으로 할당)으로 일을 분산합니다.
- Broadcast: b와 유사하나 데이터를 모든 곳에 동시에 던집니다.
- Source: 데이터가 접근 가능한 곳에서 일을 수행하는 식입니다. 보통 single 혹은 hash가 가장 많이 사용되며, 여기에서는 hash 유형으로 실행되었습니다.
- 필터링된 데이터를 전달합니다.
- WHERE조건이 없는 테이블은 다른 분기에서 수행되고, 여기서는 필요한 키만 찾아서 ScanProject 되는 것을 볼 수 있습니다.
- 필요한 키값을 찾아 전달합니다.
- 2와 4의 값에 INNER JOIN 을 취합니다.
- 이 값의 id에 aggregate(distinct 용)를 수행합니다.
- 이 값을 최종 노드로 전달하고, 다시 최종 노드에서 aggregate를 수행한 후 결과값으로 수집해서 전달합니다.
정말 별 것 없습니다.
여기에 더불어, 수행 시간이나 대략 사용하는 데이터의 크기를 보고 싶으면 EXPLAIN ANALYZE 구문을 사용할 수 있습니다.
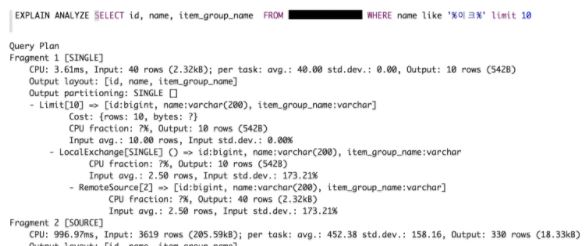
여기서는 각 부분에서 사용하는 리소스(CPU, 사용 추정 행 수 등)가 표시됩니다. 데이터의 수는 추정치지만 평균 및 표준 편차도 같이 표시해 주므로 대략적인 양을 산정할 수 있습니다. 더불어 각 부분 옆에 SINGLE, SOURCE, HASH 등 앞서 설명한 각 부분에서 처리하는 방식이 같이 나와있어서 보다 상세히 작동 방식을 이해할 수 있습니다.
장점 및 주의사항
이를 통해 얼마나 많은 데이터가 필요하고, 리소스는 얼마나 필요한 지를 어림짐작할 수 있습니다. 특히 프레스토는 데이터 소스에서 데이터를 가지고 와서 최종적으로는 메모리에 올려서 연산 처리를 하다 보니 데이터의 양을 어느 정도 추정할 수 있게 되면 메모리에 과부하가 가서 쿼리 결과가 안 나오는 사태가 발생한다든가 하는 일을 미연에 방지할 수 있습니다. 다만 이는 추정치고, 프레스토에서는 타 소스에서 데이터를 가지고 와서 자체 연산을 하는 식이다보니 정확도가 DB의 쿼리 실행계획보다는 다소 낮다는 사실을 인지하고 있어야 합니다 (특히 쿼리 실행 계획을 확인한 때와 실제 쿼리를 실행하는 때가 다르다 보면 사용 가능한 CPU 나 메모리가 다르고, 이에 따라 예상 속도가 다르고, 어떤 경우에는 실행 계획 자체가 일부 바뀌기도 합니다).
마무리하며
기획부터 개발까지, 다양한 분야에서 점차 많은 분야에서 데이터를 활용하게 되고, 이를 위해서는 데이터를 당연히 조회하게 됩니다. 그러면서 데이터 조회에 대한 이야기도 많이 하게 되는데, 이 때 가장 많이 하는 이야기는 ‘원하는 것을 정확히 생각하고, 그 것이 어떤 데이터로 만들어져야 하는지, 그 데이터가 어떻게 구해지는 지 계속 생각하는 것’입니다. 데이터는 예민하고, 각도에 따라 모습이 너무 달라지기 때문에, 생각하지 않고 기계적으로 하다 보면 무언가를 놓치게 됩니다. 이를 위해서, 본인이 어떤 코드를 만들었고, 그 것이 어떤 형태로 데이터를 만들어서 본인에게 오게 되는지를 생각하는 것이 필요합니다. 쿼리 실행 계획을 확인하는 것은 이런 데에 정말 많은 도움이 됩니다. 특히 프레스토의 경우에는 동작 구조와 일부 형태만 알면 실행 계획은 매우 단순하므로 쉽게 이해할 수 있고, 한 번 이해하면 이후에 정말 여러 모로 유용하게 사용할 수 있을 것이라고 생각합니다.
(본 내용은 우아한형제 기술블로그에도 동일하게 올라가 있습니다)